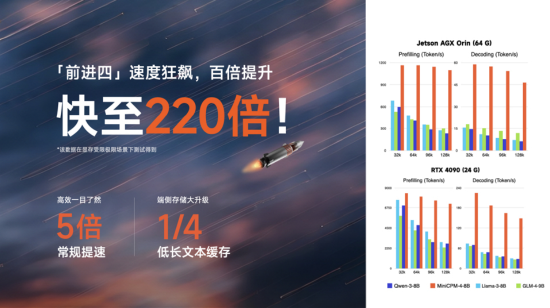
新浪科技讯 6月10日下午消息,近日,面壁智能第四代“面壁小钢炮” MiniCPM4.0 端侧模型(代号“前进四”)发布。据悉,第四代小钢炮拥有 8B 、0.5B两种参数规模,实现了同级最佳的模型性能。可让长文本、深思考在端侧真正跑起来,实现220倍极限加速。
其中,MiniCPM 4.0-8B 模型为稀疏注意力模型,在MMLU、CEval、MATH500、HumanEval等基准测试中,以仅22%的训练开销,性能比肩 Qwen-3-8B、超越Gemma-3-12B。MiniCPM 4.0-0.5B在性能上,也较更大的Qwen-3-0.6B、Llama 3.2实现仅2.7%的训练开销,一半参数性能翻倍,并实现了最快 600 Token/s的极速推理速度。
相较于Qwen-3-8B、Llama-3-8B、GLM-4-9B等同等参数规模端侧模型,实现了长文本推理速度5倍常规加速以及最高 220倍加速(显存受限极限场景下测出),让端侧模型长文本推理“快如闪电”。面壁智能联合创始人兼首席科学家刘知远在与新浪科技沟通中表示,“最高220倍加速,其实是建立在我们模型架构、数据治理、软硬件结合、训练等方面全栈创新优化成果之上的。”
刘知远指出,220倍的加速看上去比较夸张,但本身其实存在一个特殊性——由于MiniCPM4.0 在处理更长序列的数据时,可以更好地去处理Transformer架构带来的内存爆炸问题,避免了长序列数据处理带来的内存占用倍增,而同尺寸的Qwen-3-8B、Llama-3-8B等模型并未就此进行优化,因此MiniCPM4.0有了突出的表现。
据悉,MiniCPM 4.0 模型采用的InfLLMv2稀疏注意力架构改变了传统 Transformer 模型的相关性计算方式,有效摆脱了逐字重复计算的低效,将稀疏度从行业普遍的40%-50%,降至极致的5%,注意力层仅需1/10的计算量即可完成长文本计算。且对算子底层重写,进一步加速提升,并使得对文本相关性精准性大大提升。
值得一提的是,DeepSeek 使用的长文本处理架构NSA(Native Sparse Attention)也引用并采用了与InfLLM相同的分块注意力计算思路,但其对于短文本的推理较慢,InfLLMv2则很好地解决了NSA在短文本推理上的短板。
在缓存消耗上,MiniCPM 4.0-8B在 128K 长文本场景下相较于Qwen3-8B仅需 1/4 的缓存存储空间。在速度、性能飙升的同时,又做到了模型极致压缩,让端侧算力不再有压力。
据悉,基于 8B 版本,面壁智能已微调出两个特定能力模型,分别可以用作 MCP Client 和纯端侧性能比肩Deep Research的研究报告神器MiniCPM4-Surve。截至目前,面壁小钢炮 MiniCPM 系列全平台下载量累计破1000万。(文猛)